تعلُّم الآلة (Machine Learning) هو فَرعٌ من فروع الذكاء الاصطناعي يركِّز على إنشاء خوارزميات ونماذجَ تسمح لأجهزة الحاسوب بالتعلم من البيانات وإجراء التنبؤات أو القرارات دون برمجتها برمجةً مباشرة. يتضمن تدريب نموذج على مجموعة بيانات للتعرف على الأنماط، ولتحسين أدائه بمرور الوقت عندما يتعرض لمزيد من البيانات. تبدأ العملية بـالإدخال ويتكون من البيانات المُقدَّمة إلى النموذج مثل الصور أو النصوص أو القيم الرقمية، ثم يحلِّل النموذج هذه البيانات أثناء المعالجة باستخدام الخوارزميات لتحديد الأنماط والعلاقات. وأخيرًا المخرجات التي تتكوَّن من التنبؤات أو القرارات التي يتخذها النموذج مثل تصنيف صورة، أو إنشاء نص، أو التوصية بالمنتجات. يمكن أن يكون تعلم الآلة خاضعًا للإشراف، أو غير خاضع للإشراف، أو شبه خاضع للإشراف، أو من نوع التعليم المعزز. ويمكن تقييم كفاءة نموذج تعلم الآلة عن طريق استخدام
مقياس تربيع معدل الخطأ {{مقياس تربيع معدل الخطأ: (Mean Square Error) مقياس رياضي يُستخدم لتقييم دقة نماذج تعلم الآلة، من خلال حساب مربع الفرق بين القيم المتنبأ بها والقيم الحقيقية. وكلما كانت قيمته أقل، كان النموذج أدقَّ في التنبؤ وأفضل أداءً.}} ومدى الانحياز (Bias) ومدى التغيُّر (Variance) والمصادقة المتقاطعة (Cross validation) وغيرها.
تاريخه
أشار آلان تورينغ (Alan Turing، 1912 -1954) في بحثه عام 1950 بعنوان "ماكينات الحوسبة والذكاء" إلى
اختبار تورينغ {{اختبار تورينغ: (Turing Test) اختبار وضعه آلان تورينغ عام 1950 لقياس قدرة الحاسوب على محاكاة الذكاء البشري. يعتمد على محادثة يجريها حكم بين إنسان وآلة، فإذا لم يستطع الحكم التمييز بينهما، تكون الآلة قد نجحت في الاختبار، ما يشير على ذكائها.}}[1]، وكان محور الاختبار السؤال الآتي: هل يمكن للحاسوب تجاوز "ما نحن نعرفه ونطلبه"، والتعلُّم من تلقاء نفسه كيفية أداء مهمة محددة؟
يتكون تعلم الآلة من التقنيات التي تُمكِّن أجهزة الحاسوب من اكتشاف الأشياء من البيانات، التي تمكِّننا من بناء تطبيقات الذكاء الاصطناعي. لم تكن بعض المشكلات قابلة للحل من خلال التقنيات المُبكِّرة المستخدمة في الذكاء الاصطناعي؛ إذ لم تعمل الخوارزميات ذات الحالات الثابتة (Hard-coded) أو الأنظمة المستندة إلى القواعد
[2](Rule-Based System) عملًا جيدًا لبعض المشكلات مثل التعرف على الصور (Image Recognition)، أو استخراج المعنى من النص (Extracting Meaning From Text). يُدخِل البشر في البرمجة الكلاسيكية للذكاء الاصطناعي القواعد من خلال بناء برنامج، وتُعالَج البيانات وفقًا لهذه القواعد (الشكل 1).
[الشكل1]
 الفرق بين البرمجة التقليدية وتعلم الآلة
الفرق بين البرمجة التقليدية وتعلم الآلة
حذف الصورة؟
سيؤدي هذا إلى نقل الصورة إلى سلة المهملات.
أما مع تعلم الآلة فَيُدخِل البشر البيانات، بالإضافة إلى الإجابات المتوقعة من البيانات نفسها، وتكون المخرجات هي القواعد. يمكن بعد ذلك تطبيق هذه القواعد على بيانات جديدة لإنتاج إجابات بناءً على ما تُعلِّم من البيانات السابقة. يُدرَّب نظام تعلم الآلة بدلًا من برمجته برمجة واضحة، على سبيل المثال، إذا رغب شخص في أتمتة مهمة تصنيف صور عطلته فيمكن له أن يقدم لنظام تعلم الآلة العديد من الأمثلة مع صور يُصنِّفها الشخص نفسه (منظر طبيعي، داخل المدينة ...)، وسيتعلم النظام القواعد الإحصائية من خلال ربط الصور بالتصنيفات المحددة، فهكذا تُغذّى الخوارزمية بالكثير من البيانات لتكتشف الأشياء مثل المعاملات المالية لتحديد معاملات الاحتيال (Fraudulent) من خلال التدريب حتى تتمكن من التنبؤ بالاحتيال في المستقبل، أو تُزوَّد بمعلومات حول قاعدة العملاء لتكتشف أفضل طريقة لتقسيمها. وفي تعلُّم الآلة هناك ثلاثة جوانبَ مهمة[3]:
- بيانات الإدخال: على سبيل المثال إذا كانت المهمة هي التعرُّف على الكلام، فهذه البيانات قد تكون ملفات صوتية لأشخاص يتحدثون، وإذا كانت المهمة هي معرفة محتوى الصور الرئيس فإن المدخلات هي الصور.
- أمثلة على المخرجات المتوقعة: في مهمة التعرف إلى الكلام يمكن أن يكون النص المكافئ للملف الصوتي والذي كتبه أشخاص استمعوا للملفات الصوتية، وفي مهمة التعرف إلى محتوى صورة فإن المخرجات المتوقعة يمكن أن تكون "كلبًا" و"قطة" وغيرهما.
- طريقة لقياس ما إذا كانت الخوارزمية تعمل عملًا جيدًا: وهذا ضروري لتحديد الفرق بين الناتج الحالي للخوارزمية وناتجها المتوقع، يُستخدَم القياس بوصفه قيمة تغذية راجعة لضبط طريقة عمل الخوارزمية. خطوة التعديل هذه هي ما نسميه التعلّم.
يحوّل نموذج تعلم الآلة بيانات الإدخال إلى مخرجات ذات معنى عن طريق التمثيل
[4](Representations)، وهو استخدام طرق مختلفة للنظر إلى البيانات، على سبيل المثال يمكن تشفير صورة ملونة بتنسيق أحمر-أخضر-أزرق (RGB) أو بتنسيق تدرج اللون، والتشبع، والقيمة (HSV)، وهذان تمثيلان مختلفان للبيانات نفسها.
بعض المهمات التي قد تكون صعبة بتمثيل معين يمكن أن تصبح سهلة مع تمثيل آخر، على سبيل المثال، إذا كانت المهمة هي تحديد كل وحدات البكسل الحمراء في ملف الصورة، فإن تمثيلها أبسطُ في تنسيق أحمر-أخضر-أزرق (RGB)، بينما يفصِّل استخدام تدرج اللون، والتشبع، والقيمة (HSV) معلومات اللون (درجة اللون) عن الكثافة (القيمة)، ما يسهِّل اكتشاف ألوان معينة وعزلها على الرغم من التغيرات في الإضاءة أو التظليل.
أنواعه
التعلم تحت الإشراف
هو نوع من التعلم يبني نموذجًا للتنبؤ بناءً على البيانات لمعرفة نتيجة نمط جديد لم يُرَ سابقًا، ويتمُّ ذلك من خلال تزويد النظام ببيانات معلّمة (Labeled)[5]، على سبيل المثال، التنبؤ بقيمٍ رقمية مثل سعر السيارة بالنظر إلى مجموعة من الميزات (المسافة المقطوعة، العمر، العلامة التجارية، وغيرها) تسمى تلك القيم قيمًا مساعدة للتنبؤ (Predictors)، ويسمّى هذا النوع من المهمات الانحدار (Regression). ولتدريب النظام فإنه يحتاج إلى إعطائه العديد من الأمثلة على السيارات بما في ذلك
القيم المساعدة للتنبؤ {{القيم المساعدة للتنبؤ: المتغيرات أو الميزات المستخدمة بوصفها مدخلات في نماذج تعلم الآلة للتنبؤ بقيمة معينة. مثل استخدام المسافة المقطوعة، والعمر، والعلامة التجارية للسيارة بوصفها قيمًا مساعدة للتنبؤ بسعرها في المستقبل.}} وأسعارها، ومن الأمثلة على طرق التعلم تحت الإشراف الجيران الأقرب (k-Nearest Neighbors)، والانحدار الخطي (Linear Regression)، والانحدار اللوجستي (Logistic Regression)، وآلة المتجهات الداعمة (Support Vector Machines (SVMs))، وشجرة اتخاذ القرار والغابات العشوائية (Decision Trees and Random Forests)، والشبكات العصبية (Neural networks).
التعلم غير الخاضع للإشراف
يصف هذا النوع كيفية ترتيب البيانات وجمعِها (Clustering)، إذ إن البيانات التي يزوَّد بها النظام غير معلّمة (Unlabeled)[6][7]، على سبيل المثال، هناك شخص لديه الكثير من البيانات حول زوار مدونته، ويرغب في تشغيل
خوارزمية التجميع {{خوارزمية التجميع: (Clustering) تقنية في التعلم غير الخاضع للإشراف، تقسم البيانات إلى مجموعات متشابهة دون الحاجة إلى تصنيف مسبق. تكتشف الخوارزمية الأنماط والعلاقات بين البيانات تلقائيًّا، ما يساعد في فَهم البيانات المعقدة وتحليلها بفعالية.}} لمحاولة الكشف عن مجموعات من الزوار المتشابهين، ستعطي الخوارزمية مثلًا أن 40 في المئة من الزوار هم من الذكور الذين يحبّون الكتب المصوَّرة، ويقرأون المدونة قراءة عامة في المساء، بينما 20 في المئة هم من عشّاق الخيال العلمي الذين يزورون المدونة خلال عطلة نهاية الأسبوع، يساعد هذا الشخصَ في جعل منشوراته تستهدف كل مجموعة بحسب اهتمامها، ومن الأمثلة على طرق للتعلم غير الخاضع للإشراف:
- التجميع (Clustering).
- التجميع بعددk من الأصناف (k-Means).
- التحليل التجميعي الهرمي (Hierarchical Cluster Analysis).
- التصور وتقليل الأبعاد (Visualization and dimensionality reduction).
- تحليل المكونات الرئيسة (Principal Component Analysis (PCA)).
- جوهر تحليل المكونات الرئيسة (Kernel PCA).
وواحدٌ من أمثلة خوارزميات التعلم غير الخاضع للإشراف الكشفُ عن الحالات الشاذة لتعامل معين (Anomaly Detection)، كالكشف عن عمليات غير معتادة على بطاقة الائتمان؛ لمنع الاحتيال، أو اكتشاف عيوب التصنيع، وفي هذه الحالة يُدرَّب النظام على الحالات الطبيعية، وعندما يرى نسخة جديدة يمكنه معرفة ما إذا كانت عادية أم لا.
التعلم شبه الخاضع للإشراف
يمكن أن تتعامل بعض الخوارزميات مع بيانات تدريب مصنفة جزئيًّا (Partially Labelled)، وعادة ما تكون الكثير من البيانات غيرَ مصنفة، والقليل منها مصنفة (Labeled)[8]، في فيسبوك، على سبيل المثال، عند تحميل صور العائلة كلها في الخدمة يتعرف فيسبوك تلقائيًّا على أن الشخص نفسه أ يظهر في الصور 1 و5 و11، بينما يظهر شخصٌ آخرُ في الصور 2 و5 و7، هذا هو الجزء غير الخاضع للإشراف من خلال استخدام خوارزمية التجميع، كل ما يحتاجه النظام الآن هو أن يُخبَرَ من هم هؤلاء الناس، فتسميةٌ واحدة فقط لكل شخص تمكِّنه من تسمية الجميع في كل صورة، وهو أمر مفيد للبحث عن الصور.
التعلّم المعزز
[الشكل2]
 رسم بياني يبيّن العلاقة بين سعر المنزل ومساحته
رسم بياني يبيّن العلاقة بين سعر المنزل ومساحته
حذف الصورة؟
سيؤدي هذا إلى نقل الصورة إلى سلة المهملات.
يسمّى نظام التعلّم في هذا السياق وكيلًا (Agent)، إذ يُراقب البيئة، ويُحدِّد الإجراءات المطلوبة، وينفذّها، ويحصل على مكافآت في المقابل (أو عقوبات)[9]. على النظام أن يتعلم من تلقاء نفسه أيّ استراتيجية (Policy) هي الفُضلى للحصول على أكبر مكافأة بمرور الوقت. تحدد الاستراتيجية الإجراء الذي يجب على
الوكيل {{الوكيل: (Agent) نظام ذكي في التعلم المعزز يراقب البيئة المحيطة، يختار الإجراءات المناسبة، وينفذها للحصول على مكافآ
ت أو تجنب عقوبات. يتعلم الوكيل من خلال التجربة والخطأ لتحسين استراتيجيته وتحقيق أفضل النتائج بمرور الوقت.}} اختياره عندما يكون في حالة معينة، على سبيل المثال، تطبِّق العديد من الروبوتات خوارزميات التعلم المعزز لتعلم كيفية المشي. وبرنامج (AlphaGo) من (DeepMind) هو مثالٌ آخرُ أيضًا على التعلم المعزز، إذ إنه تَعلَّم طريقة الفوز من خلال تحليل الملايين من الألعاب، ثم لَعِب العديد من الألعاب ضد نفسه.
لو رُسِمَت العلاقة بين سعر المنزل وحجمه كما في (الشكل 2) بناءً على هذه البيانات يمكن توقُّع المبلغ حسب مساحة المنزل. إذا وُصِلت البيانات بخط مستقيم، فإن المبلغ المُتوقَّع لمنزل مساحته 750 قدمًا مربعًا سيكون نحو 150,000 دولار. زُوِّدت الخوارزمية في هذا المثال ببيانات تحوي إجابة ما نسأل عنه، ويسمّى هذا تدريبًا (Training)، ثمَّ بعد ذلك قد تُسأَل الخوارزمية عن مساحة بيت غير موجود في البيانات لديها، ويسمّى هذا تنبؤًا (Predict).
قياس كفاءة النموذج
لقياس مدى قرب القيمة المُتنبَّأ بها من القيمة الحقيقية يُستخدَم مقياس تربيع معدل الخطأ (Mean Square Error) كما تُظهر المعادلة الآتية.
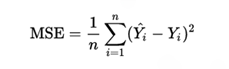 معادلة مقياس تربيع معدل الخطأ
معادلة مقياس تربيع معدل الخطأ
حذف الصورة؟
سيؤدي هذا إلى نقل الصورة إلى سلة المهملات.
وهو يحسب تربيع معدّل الاختلاف (أو الخطأ) بين القيمة المُتنبَّأ بها من خلال نموذج التعلم (Learning Model) والقيمة الحقيقية، ومن المقاييس الأخرى المستخدمة أيضًا لقياس مدى كفاءة نموذج (Model Evaluation) التنبؤ
مدى الانحياز (Bias)، ومدى التغير (Variance)، والمصادقة المتقاطعة (Crossvalidation) [10].
مدى الانحياز
يُشير الانحياز في تعلم الآلة إلى الخطأ الذي يحصل عند بناء نموذج تعلم بسيط (خطي) بناء على معلومات حقيقية، ولكن العلاقة بين البيانات أكثر تعقيدًا ممّا يؤدّي الى حصول خطأ في التنبؤ من خلال بعض الانحياز (Bias) عند تقدير بعض القيم. بغضِّ النظر عن حجم البيانات المُتوفِّرة لبناء نموذج التدريب، فإنه من المستحيل إنتاج نموذج يتنبَّأ تنبُّؤًا دقيقًا إذا كان النموذج بسيطًا، ولكن العلاقة بين البيانات أكثر تعقيدًا، فعلى سبيل المثال، لو كان التنبؤ بأسعار المنازل بناءً على مساحتها فقط، وكانت هناك عواملُ أخرى مؤثرة مثل الموقع، وعدد الغرف، وجَودة البناء، فإن تجاهل هذه العوامل سيؤدّي إلى نموذج غير دقيق؛ لأن العلاقة بين المساحة والسعر ليست بسيطة.
مدى التغير
[الشكل3]
 والتغير (Variance) في دقة النموذج/تأثير الانحياز (Bias) والتغير (Variance) في دقة النموذج.svg) تأثير الانحياز (Bias) والتغير (Variance) في دقة النموذج
تأثير الانحياز (Bias) والتغير (Variance) في دقة النموذج
حذف الصورة؟
سيؤدي هذا إلى نقل الصورة إلى سلة المهملات.
يُشير التغير (Variance) إلى مقدار التغير في تقدير القيم المُتنبَّأ بها إذا غُيِّرت البيانات التي يُعلَّم بها النموذج، وفي الوضع المثالي فإنّه لا يُتوقَّع اختلافٌ كبير في التنبؤ بالقيم إذا دُرِّب النموذج من خلال بيانات مختلفة، ولكن إذا كانت الطريقة المستخدمة لبناء النموذج حساسة لهذا التغيير، فإن استخدام بيانات مختلفة لتعليم النموذج سيؤدي إلى تغير كبير في القيم المتنبأ بها. الهدف دائمًا بناءُ نموذج قليل الانحياز وقليل التغير (Low Variance And Low Bias)، أما النموذج المثالي فهو الذي يقدِّم تنبؤات دقيقة، بصرف النظر عن تعقيد العلاقة بين البيانات أو التغير في البيانات المستخدمة للتدريب (الشكل 3).
المصادقة المتقاطعة
المصادقة المتقاطعة (Cross validation) هي عملية للتأكُّد من مدى ثبات (Stability) النموذج، ومن أن معظم النتائج من النموذج صحيحة، أو بعبارة أخرى التأكُّد من أن النموذج قليل الانحياز وقليل التغير (Low Variance And Low Bias). والتحقق (Validation) هو عملية فحص النموذج من خلال القيم التي دُرِّب عليها، ولكن هذه الطريقة وحدها لا تضمن فاعلية النموذج في التنبؤ بقيم لم يرَها من قبل (ليست من بيانات التدريب)، تأتي هنا أهمية المصادقة المتقاطعة، إذ تُقسَّم البيانات إلى جزئين: جزء لتدريب النموذج، وجزء لاختباره بعد البناء، للتأكد من مدى فعالية النموذج. فإذا أراد المستخدم نموذجًا لتصنيف أنواع الزهور مثلًا، يمكنه تقسيم بيانات الزهور إلى قسمين: قسم لتدريب النموذج، وقسم آخرَ لاختباره. يساعد هذا في التأكد من أن النموذج يمكنه التنبؤ تنبُّؤًا صحيحًا بأنواع الزهور الجديدة التي لم يرَها من قبلُ.
أمثلة على خوارزميات تعلم الآلة
خوارزميات تعلم الآلة هي تقنيات تُستخدَم لتعليم الآلات كيفيةَ أداء المهمات دون الحاجة إلى برمجتها برمجةً صريحة. بدلاً من ذلك، تتعلم الآلات من البيانات، إذ تحلِّل الخوارزميات البيانات[11]، وتحدّد الأنماط لإنشاء نموذج يمكنه التنبؤ أو اتخاذ القرارات بناءً على البيانات الجديدة. بعض هذه الخوارزميات: الانحدار اللوجستي (Logistic Regression)، وشجرة اتخاذ القرار (Decision Trees)، والخوارزمية التصنيفية (k-means Clustering)، وآلة المتجهات الداعمة (Support Vector Machines).
الانحدار اللوجستي
الانحدار اللوجستي (Logistic Regression) هو خوارزمية تصنيف تُستخدَم للتنبؤ بإحدى فئتين محتملتين، يُفضَّل استخدامها في التصنيف الثنائي عندما يُحتاج إلى تصنيف البيانات إلى فئتين مثل البريد الإلكتروني إلى مزعج أو غير مزعج (Spam and Not Spam)، أو تحديد إذا ما كانت العملية الحاصلة على بطاقة الائتمان احتيالًا أم لا (Fraud Detection Credit Card)، أو استخدام حجم الخلية لتحديد ما إذا كان الشخص مصابًا بالسرطان أم لا. في الانحدار اللوجستي يمكن تحليل تأثير كل ميزة على الاحتمالات بسهولة، مثالُ ذلك استخدامه في شركات البريد الإلكتروني مثل جي ميل (Gmail) لتصنيف الرسائل بوصفها رسائلَ مزعجة أو غير مزعجة بناءً على محتوى الرسائل، والعناوين، والمعلومات الأخرى.
شجرة اتخاذ القرار
[الشكل4]
 مثال على شجرة اتخاذ القرار للتنبؤ بجنس الشخص بناءً على الوزن
مثال على شجرة اتخاذ القرار للتنبؤ بجنس الشخص بناءً على الوزن
حذف الصورة؟
سيؤدي هذا إلى نقل الصورة إلى سلة المهملات.
شجرة اتخاذ القرار (Decision Trees) هي خوارزمية تُستخدم لكلٍّ من مهمات التصنيف والتنبؤ، يُفضَّل استخدامها نظرًا إلى سهولة تفسيرها، تُظهر عملية اتخاذ القرار في شكلٍ بيانيّ يشبه الشجرة؛ ما يسهِّل تفسير النتائج، كما أنها قادرة على التعامل مع كلٍّ من البيانات النوعية والكمّية، مثالُ ذلك استخدامها في مجال الطبّ لتشخيص الأمراض بناءً على مجموعة من الأعراض والفحوصات الطبية، إذ تساعد في اتخاذ قرارات واضحة بناءً على المعلومات المتاحة.
فإذا كان هناك مثلًا بيانات بمتغيِّرينِ اثنين كمدخلات (الوزن والطول)، وكانت النتيجة هي تحديد جنس الشخص (ذكر أو انثى)، فيمكن بناء شجرة اتخاذ قرار (الشكل 4).
الخوارزمية التصنيفية
الخوارزمية التصنيفية (k-means) هي تقنية غير إشرافية تُستخدم لتقسيم مجموعة من البيانات إلى (مجموعات k) أو عناقيد (Clusters)، يُفضَّل استخدامها في تحليل البيانات الاستكشافية عندما يُراد تقسيم البيانات إلى مجموعات لفَهم الأنماط الأساسية دون الحاجة إلى معرفة الفئات مسبقًا، كما تُستخدم لتقليل الأبعاد، واكتشاف الأنماط في البيانات المعقدة، مثال ذلك استخدامها في التسويق لتجزئة العملاء إلى مجموعات بناءً على سلوكيات الشراء؛ ما يساعد الشركات في تطوير استراتيجيات تسويقية مخصصة لكل مجموعة.
آلة المتجهات الداعمة
آلة المتجهات الداعمة (Support Vector Machines) هي خوارزمية تصنيف غير إحصائية (Non-probabilistic Linear Classifier)، تُستخدم لتحديد الفئة الفُضلى من بين فئتين من البيانات من خلال إيجاد أفضل خط فاصل (Hyperplane) يفصل بين الفئتين. يُفضَّل استخدامها عندما تكون البيانات تحوي عددًا كبيرًا من السمات أو المتغيرات (عالية الأبعاد)، ويُحتاج إلى فصلها بفاعلية، كما تُستخدم عندما يُحتاج إلى تقليل الأخطاء، وتصنيف البيانات بدقة عالية، مثالُ ذلك استخدام آلة المتجهات الداعمة في مجال التعرف إلى الوجه لتصنيف الصور إلى فئات مثل الوجوه البشرية وغير البشرية، ما يساعد في تطبيقات الأمن والمراقبة.
[الشكل5]
/مثال يوضّح كيفية فصل النقاط باستخدام طريقة آلة المتجهات الداعمة (SVM).svg) مثال يوضّح كيفية فصل النقاط باستخدام طريقة آلة المتجهات الداعمة (SVM)
مثال يوضّح كيفية فصل النقاط باستخدام طريقة آلة المتجهات الداعمة (SVM)
حذف الصورة؟
سيؤدي هذا إلى نقل الصورة إلى سلة المهملات.
في طريقة آلة المتجهات الداعمة (SVM)، يجب تحديد النقاط الأقرب إلى
الخط الفاصل {{الخط الفاصل: حد رياضي يفصل بين فئتين مختلفتين من البيانات في خوارزمية آلة المتجهات الداعمة. يهدف النموذج لإيجاد أفضل خط فاصل يحقق أكبر مسافة ممكنة بين الفئات، ما يضمن تصنيفًا دقيقًا وواضحًا للبيانات الجديدة.}} بين الفئتين المختلفتين، وتسمّى هذه النقاط بـدعامات الدعم (Support Vectors). بعد ذلك، تُحسب المسافة بين الخط الفاصل وهذه النقاط، وتسمّى هذه المسافة بـالهامش (Margin). هدف خوارزمية آلة المتجهات الداعمة هو العثور على أكبر هامش ممكن، بحيث يكون الخط الفاصل بين الفئتين هو الأفضل، ما يعني أن الفئات تكون مفصولة بأكبر قدر من الوضوح (الشكل 5).
تعلم الآلة التلقائي والتعلم الفوقي
يعد
تعلم الآلة التلقائي (AutoML) والتعلم الفوقي (Meta-Learning) من الاتجاهات الناشئة التي تهدف إلى تقليل الجهد اليدوي المطلوب لتطوير نماذج تعلم الآلة. يركِّز تعلم الآلة التلقائي على أتمتة عملية اختيار النموذج، وضبط المعلمات الفائقة، وهندسة الميزات. يتضمَّن التعلم الفوقي (Meta-Learning) أو "تعلم التعلم" تطوير خوارزميات يمكنها التكيف مع المهمات الجديدة بأقلّ قَدْر من
بيانات التدريب {{بيانات التدريب: مجموعة البيانات المستخدمة لتعليم نماذج تعلم الآلة التعرف إلى الأنماط والعلاقات. تحتوي على أمثلة متنوعة تساعد النموذج في التعلم وتحسين أدائه؛ حتى يتمكن من التنبؤ بدقة عند التعامل مع بيانات جديدة لم يرَها من قبلُ.}} من خلال الاستفادة من المعرفة من المهمات السابقة.
تعدّ هذه المنهجيات ذاتَ قيمة خاصّة في السيناريوهات التي تكون فيها الخبرة في المجال محدودة، أو حيث يلزم النشر السريع لنماذج تعلم الآلة. لقد سهَّلت منصات تعلم الآلة التلقائي مثل (AutoML) من جوجل، و(Azure AutoML) من مايكروسوفت تطوير نماذج تعلم الآلة ونشرها من غير المختصين، فعلى سبيل المثال، في تجارة التجزئة يمكن لـتعلُّم الآلة التلقائي تحديد أفضل خوارزمية تلقائيًّا، وضبط المعلمات الفائقة، وبناء نموذج للتنبؤ بسلوك الشراء لدى العميل دون الحاجة إلى خبرة عميقة في تعلم الآلة.
التعلم الفيدرالي وحفظ الخصوصية في تعلم الآلة
مع تزايد القلق بشأن خصوصية البيانات، هناك اهتمامٌ كبير بالتعلم الفيدرالي الذي يحافظ على الخصوصية. يتيح التعلم الفيدرالي تدريب النماذج عبر الأجهزة اللامركزية مع الحفاظ على البيانات محليةً، ما يعني الحفاظ على الخصوصية، يُسمح مثلًا لتطبيق الهاتف الذكي بتحسين ميزة النص التنبؤي (Predictive text) من خلال التعلم من بيانات المستخدم عبر أجهزة متعدّدة دون نقل البيانات إلى خادم مركزي، إذ يقوم كل جهاز بتدريب النموذج محليًّا باستخدام بياناته، وتُشارَك معلمات النموذج المحدثة فقط، لا البيانات الأولية. يستكشف الباحثون أيضًا التقنيات التي تضيف تشويشًا إلى البيانات أو معلمات النموذج لحماية الخصوصية الفردية مع السماح بالتعلم الفعال؛ ما يجعل تتبُّع المعلومات مرة أخرى إلى أي مستخدم محدد أمرًا مستحيلًا مع الاستمرار في تحسين النموذج العام. تعدّ هذه المنهجيات ضرورية للتطبيقات التي تتضمن بيانات حساسة، مثل الرعاية الصحية والتمويل، إذ تكون خصوصية البيانات ذات أهمّية قصوى.
الأخلاقيات والعدالة في تعلم الآلة
مع انتشار أنظمة تعلم الآلة انتشارًا متزايدًا في التطبيقات اليومية للمستخدمين اكتسبت قضايا الأخلاقيات والعدالة أهمية كبيرة. يطوِّر الباحثون منهجيات للتأكد من أن نماذج تعلم الآلة لا تؤدي إلى إدامة أو التحيزات الموجودة في بيانات التدريب أو تفاقمها، ويتضمَّن ذلك تطوير تقنيات للكشف عن التحيز وخوارزميات التعلم المدركة للعدالة (Fairness-Aware Learning Algorithms)، وطرق ضمان عدالة النماذج عبر مختلف الفئات الديموغرافية[12]. في خوارزميات التوظيف، على سبيل المثال، يمكن تطبيق قيود العدالة لضمان أن المرشَّحين من مجموعات ديموغرافية مختلفة، مثل الجنس أو العرق، لديهم فرصٌ متساوية في الاختيار لمقابلة عمل، يمكن أثناء التدريب توجيه النموذج لتقييم المؤهلات بالتساوي بين جميع المجموعات، وبعد تدريب النموذج، يمكن لتقنيات ما بعد المعالجة تعديل اختيارات المقابلة النهائية لتصحيح أيّ تحيُّز غير مقصود، ما يضمن أن تكون عملية التوظيف عادلة لجميع المتقدمين.
يتطور مجال تعلم الآلة تطوّرًا مستمرًّا، وتظهر العديد من الاتجاهات المستقبلية في منهجيات البحث، وتشمل:
أولًا: الاستدلال السببي في تعلم الآلة، دمج الاستدلال السببي مع تعلم الآلة لتطوير نماذجَ لا تتنبأ بالنتائج فحسب، بل تفهم العلاقات السببية الأساسية أيضًا؛
ثانيًا: التعلم الآلي المستدام، معالجة التأثير البيئي لأبحاث التعلم الآلي من خلال تطوير خوارزميات موفرة للطاقة، وتعزيز استخدام الطاقة المتجددة في الموارد الحاسوبية؛
ثالثًا: العلوم التعاونية والمفتوحة في تعلُّم الآلة، تشجيع التعاون، ومشاركة التعليمات البرمجية ومجموعات البيانات والنماذج لتسريع وتيرة أبحاث تعلم الآلة وتعزيز إمكانية التكرار.
المراجع
العربية
أبودوش، إياد.
تعلم الآلة من خلال التطبيق: خوارزميات تعلم الآلة. طبعة إلكترونية، 2020. في:
https://acr.ps/1L9BP2Q
الأجنبية
Chollet, François.
Deep learning with Python. New York: Manning, 2018.
Epstein, Robert, Gary Roberts & Grace Beber (eds.).
Parsing the Turing Test:
Philosophical and Methodological Issues in the Quest for the Thinking Computer. New York: Springer, 2007.
Grosan, Crina & Ajith Abraham.
Intelligent Systems: A Modern Approach. Intelligent Systems Reference Library 17. Berlin: Springer, 2011.
Guan, Xingquan & Henry Burton. “Bias-variance tradeoff in machine learning: Theoretical formulation and implications to structural engineering applications.”
Structures. vol. 46 (December 2022). pp. 17-30.
Hastie, Trevor, Robert Tibshirani & Jerome Friedman.
The Elements of Statistical Learning. 2nd ed. New York: Springer, 2009.
Qin, S. Joe & Leo H. Chiang. “Advances and opportunities in machine learning for process data analytics.”
Computers & Chemical Engineering. vol. 126 (July 2019). pp. 465-473.
Sangaiah, Arun Kumar (ed.). Deep Learning and Parallel Computing Environment for Bioengineering Systems. Amsterdam: Elsevier, 2019.
Vassilev, Apostol et al.
Adversarial Machine learning: A Taxonomy and Terminology of Attacks and Mitigations. Gaithersburg: National Institute of Standards and Technology, 2024.
[1] Alan M. Turing, “Computing Machinery and Intelligence,” in: Robert Epstein, Gary Roberts & Grace Beber (eds.),
Parsing the Turing Test:
Philosophical and Methodological Issues in the Quest for the Thinking Computer (New York: Springer, 2007), pp. 23-65.
[2] Crina Grosan & Ajith Abraham, “Rule-based expert systems,” in: Crina Grosan & Ajith Abraham,
Intelligent Systems: A Modern Approach, Intelligent Systems Reference Library 17 (Berlin: Springer, 2011), pp. 149-185.
[3] Syed Muzamil Basha & Dharmendra Singh Rajput, “Survey on Evaluating the Performance of Machine Learning Algorithms: Past Contributions and Future Roadmap,” in: Arun Kumar Sangaiah (ed.), Deep Learning and Parallel Computing Environment for Bioengineering Systems (Amsterdam: Elsevier, 2019), pp. 153-164.
[4] François Chollet,
Deep learning with Python (New York: Manning, 2017).
[5] إياد أبودوش،
تعلم من خلال التطبيق: خوارزميات تعلّم الآلة (طبعة إلكترونية، 2020)، في:
https://acr.ps/1L9BP2Q
[6] المرجع نفسه.
[7] Trevor Hastie, Robert Tibshirani & Jerome Friedman,
The Elements of Statistical Learning, 2nd ed. (New York: Springer, 2009).
[8] أبودوش.
[9] المرجع نفسه.
[10] Xingquan Guan & Henry Burton, “Bias-variance tradeoff in machine learning: Theoretical formulation and implications to structural engineering applications,”
Structures, vol. 46 (December 2022), pp. 17-30.
[11] S. Joe Qin & Leo H. Chiang, “Advances and opportunities in machine learning for process data analytics,”
Computers & Chemical Engineering, vol. 126 (July 2019), pp. 465-473.
[12] Apostol Vassilev et al.,
Adversarial Machine learning: A Taxonomy and Terminology of Attacks and Mitigations (Gaithersburg: National Institute of Standards and Technology, 2024).
